Memory Architectures for Agentic AI: From Theory to Implementation
The Goldfish Problem
Every few minutes, an AI agent loses its mind. Not metaphorically—literally. The agent forgets critical context from earlier in the conversation, repeats previously discussed solutions, and asks questions it already answered five turns ago. Users notice. They report feeling like they're talking to someone with severe short-term memory loss, constantly reintroducing themselves to an assistant that should remember them.
This is the "Goldfish Problem," and it's the defining limitation preventing LLM-based agents from becoming truly autonomous. An agent without persistent, structured memory is fundamentally reactive rather than proactive. It can respond brilliantly to individual queries but cannot learn from experience, build on previous interactions, or maintain coherent long-term goals.
The problem isn't context windows. Extending context to 128k, 200k, or even 1M tokens doesn't solve the core issue—agents need selective memory, not just longer short-term buffers. They need to consolidate experiences, extract meaningful patterns, update beliefs based on new information, and retrieve relevant context efficiently. In short, they need memory architectures that mirror cognitive systems, not just bigger RAM.
Recent research in 2025-2026 has produced significant advances in agent memory systems: unified frameworks that manage both short-term and long-term memory (AgeMem), hierarchical architectures for long-running agents (HiMem, MemGPT), and semantic consolidation strategies that transform raw interactions into structured knowledge. This article explores the theoretical foundations, architectural patterns, and implementation strategies that define the current state of memory systems for agentic AI.
Theoretical Foundations: Memory Types in Cognitive Architecture
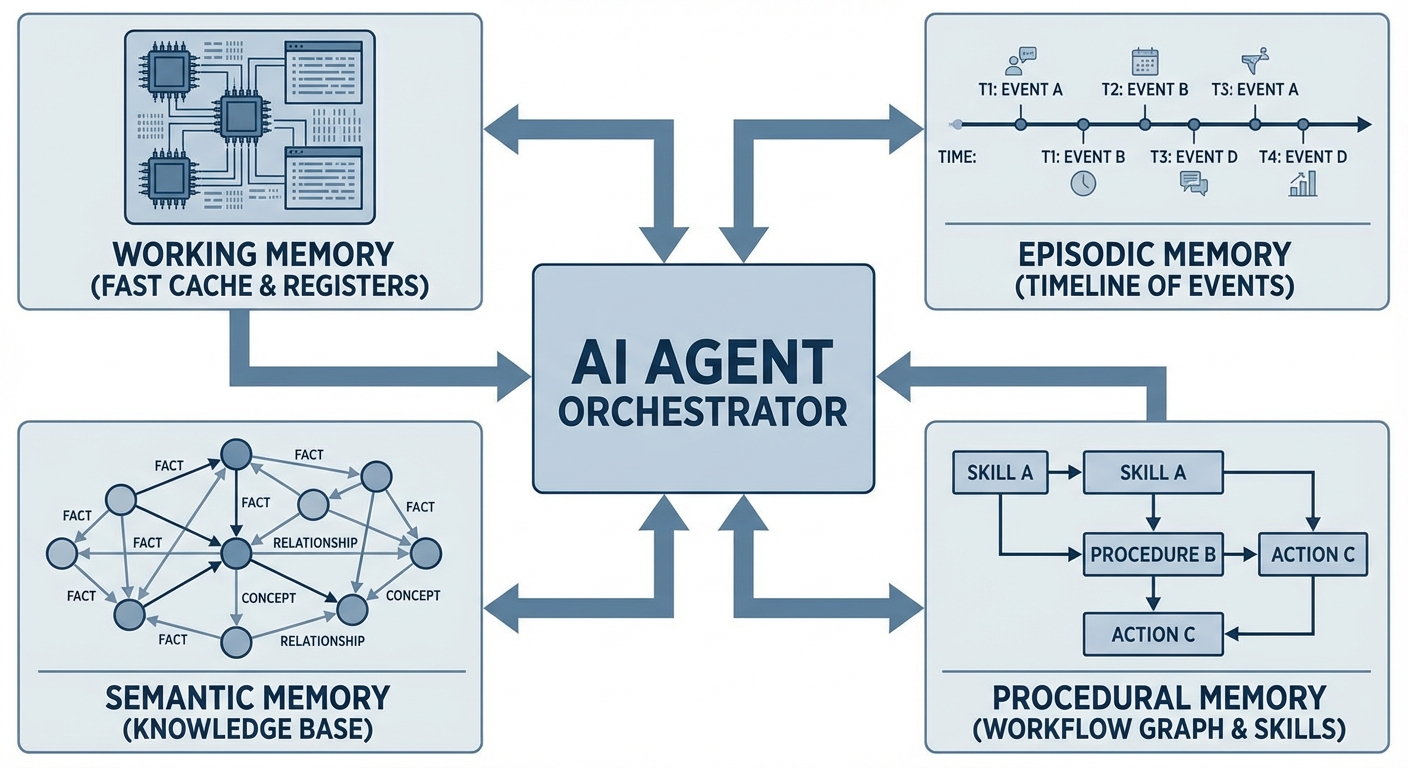
Human memory isn't a monolithic store. Cognitive science distinguishes multiple memory systems, each specialized for different types of information and retrieval patterns. Effective agent architectures mirror this specialization, implementing distinct subsystems for different cognitive functions.
Working Memory: The Active Scratchpad
Working memory holds information actively being processed—the current conversation, intermediate reasoning steps, and variables shared between agent components. This is analogous to CPU registers or L1 cache: fast, small, and frequently overwritten.
In agentic systems, working memory typically maps to the LLM's context window, constrained by token limits (4k-128k depending on the model). The critical challenge is what to retain when this buffer fills: discard old context entirely, compress via summarization, or flush specific items to long-term storage?
LangGraph's Checkpointer abstraction exemplifies this pattern, storing conversation state in databases (Redis, PostgreSQL) with configurable retention policies. The working memory serves as the agent's "consciousness"—what it's actively thinking about right now.
Episodic Memory: Remembering Experiences
Episodic memory stores specific events tied to temporal context: "Last Tuesday, the user reported a bug in the authentication flow." This differs from semantic memory (discussed next) in its specificity—episodic memories are experiential, timestamped, and tied to particular instances.
For agents, episodic memory enables several critical capabilities:
- Session continuity: Resuming conversations days later without losing context
- Debugging: Recalling what went wrong in previous attempts
- Personalization: Learning user preferences from past interactions
- Temporal reasoning: Understanding sequences of events and cause-effect relationships
The challenge with episodic memory is volume. Every interaction generates potential episodes, leading to unbounded growth. Effective implementations require segmentation strategies to chunk interactions into coherent episodes, consolidation to merge related memories, and decay mechanisms to prune low-value memories over time.
HiMem (Hierarchical Long-Term Memory, January 2026) addresses this with a "Topic-Aware Event-Surprise Dual-Channel Segmentation" strategy that identifies episode boundaries based on semantic topic shifts and unexpected events, preserving fine-grained temporal structure while managing memory bloat.
Semantic Memory: Facts and Knowledge
Semantic memory stores abstract, context-independent knowledge: "Paris is the capital of France," "The user prefers TypeScript over JavaScript," or "API endpoint /auth/login requires Bearer token authentication." Unlike episodic memory's specificity, semantic memory generalizes across experiences.
In agent systems, semantic memory serves as the persistent knowledge base, accumulating facts learned over many interactions. This is where RAG (Retrieval-Augmented Generation) architectures typically operate, embedding knowledge into vector stores for semantic search.
The key architectural decision is whether semantic memory remains static (populated during initialization) or dynamic (updated during runtime). Static semantic memory is simpler but inflexible; dynamic semantic memory supports learning but requires consolidation logic to handle conflicting updates. AWS AgentCore Memory (October 2025) implements dynamic semantic memory with a three-operation consolidation system: ADD new facts, UPDATE existing facts with new information, or NO-OP if the new information is redundant.
Procedural Memory: Skills and Workflows
Procedural memory encodes "how to do" knowledge: multi-step workflows, tool usage patterns, and reusable automation sequences. This is the agent's skill library, typically implemented as:
- System prompts defining behavioral instructions
- Tool/function definitions exposed to the agent
- Workflow graphs (in frameworks like LangGraph)
- Learned policies (in RL-based agents)
Procedural memory is less about retrieval and more about execution context. The challenge is making procedural knowledge adaptable: when should an agent modify its workflows based on feedback? LangMem's procedural memory support (introduced in 2025) allows agents to store and update system instructions dynamically, enabling adaptation without manual prompt engineering.
The Orchestration Layer
These memory subsystems don't operate in isolation. An effective agent memory architecture includes an orchestrator that routes information between subsystems, deciding what goes into working memory, when to consolidate episodes into semantic facts, and which procedural workflows to invoke.
This orchestration layer aligns with Global Workspace Theory from cognitive science, which posits a central "workspace" where different specialized modules compete for attention and share information. In agent architectures, the LLM itself often serves as this workspace, invoking memory operations as tool calls and reasoning about which memories to access.
From Theory to Architecture: Design Patterns
Translating cognitive memory types into software architecture requires addressing practical constraints: storage scalability, retrieval latency, consistency under updates, and integration with LLM inference. Several architectural patterns have emerged as effective solutions.
Basic Memory Architecture: Vector Store + Session State
The simplest viable agent memory combines session-based short-term memory with vector-based long-term retrieval:
Short-term: Store conversation history in a session database (Redis, PostgreSQL, in-memory). Each turn appends to the history, subject to token limits. When limits are exceeded, apply a retention policy (FIFO, summarization, or flush to long-term).
Long-term: Embed conversation chunks and store in a vector database (Pinecone, Qdrant, Chroma, Weaviate). Retrieval uses semantic similarity search on the user's current query to fetch relevant past context.
This pattern is straightforward to implement and covers basic use cases. LlamaIndex and LangChain both provide this out-of-the-box via ChatMemoryBuffer and ConversationBufferMemory abstractions.
Ideal for: Customer support chatbots handling 5-15 turn conversations, FAQ assistants, simple task automation bots, or any agent where sessions naturally conclude within a single sitting.
The limitation is scale. As conversations grow past 100+ turns, this architecture exhibits:
- Context poisoning: Irrelevant memories retrieved due to semantic similarity false positives
- Distraction: Too much retrieved context overwhelms the LLM, degrading reasoning quality
- Staleness: Old information persists without updates, leading to outdated beliefs
- Lack of structure: No distinction between facts, preferences, events, or instructions
For short-lived agents (single-session chatbots), this suffices. For long-running autonomous agents, more sophisticated architectures are necessary.
Hierarchical Memory: Managing Long-Running Agents
Hierarchical memory architectures address context overflow by introducing multiple memory tiers with different retention policies and granularities. The canonical examples are MemGPT and H-MEM.
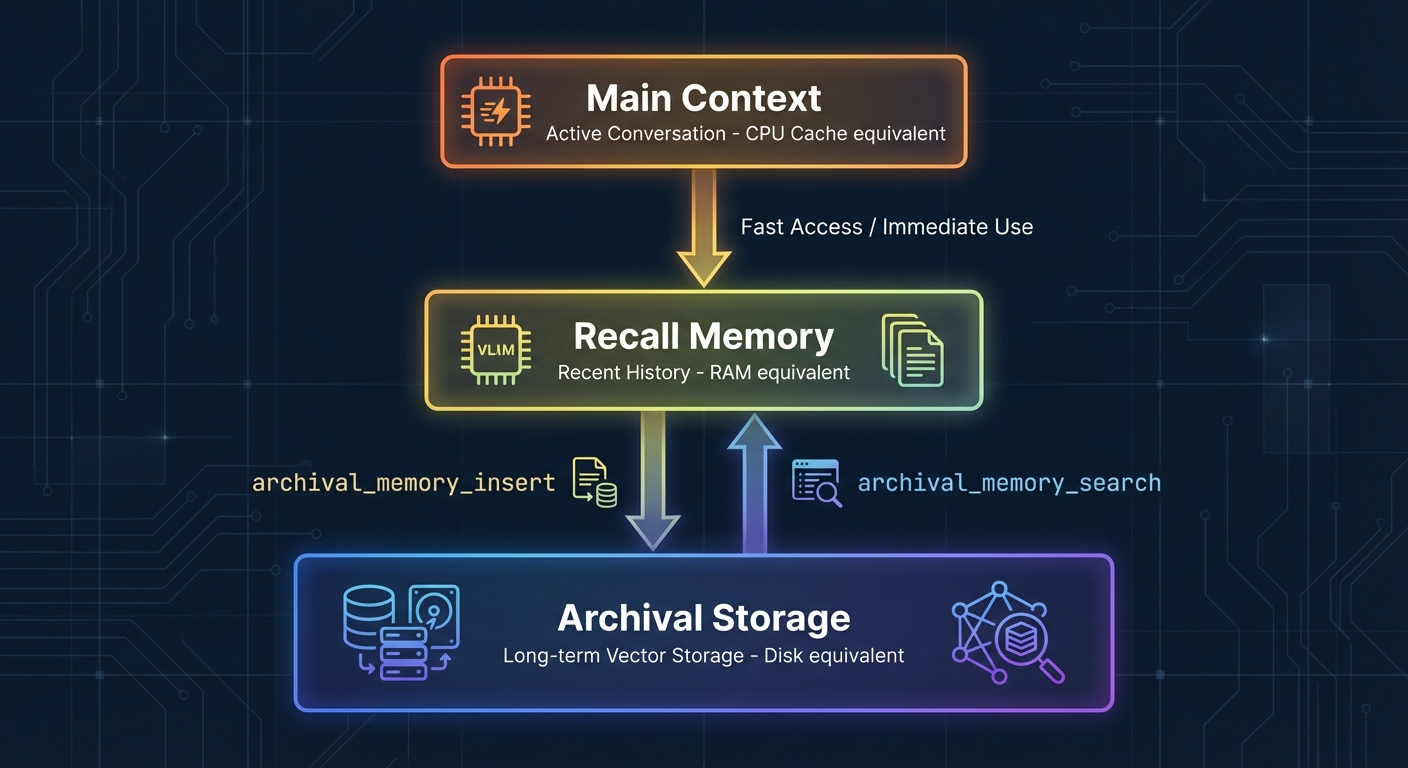
MemGPT (2023, but widely adopted in 2025) implements an OS-style memory hierarchy:
- Main context: Active conversation (equivalent to CPU cache)
- Archival memory: Long-term vector storage (equivalent to disk)
- Recall memory: Recent conversation buffer (equivalent to RAM)
The agent manages memory explicitly via tool calls: archival_memory_insert, archival_memory_search, conversation_search. This gives the LLM fine-grained control over what to remember and when to retrieve, treating memory management as a first-class reasoning task.
H-MEM (Hierarchical Memory) extends this with tiered abstraction levels. Instead of a flat archival store, H-MEM organizes memories into hierarchies: high-level summaries at the top, detailed events at the bottom. Retrieval starts at the summary level and drills down only when needed, reducing the average retrieval cost and avoiding distraction from irrelevant details.
The advantage of hierarchical architectures is efficiency for agents with 100+ turn conversations or multi-day continuity. Ideal for: Personal AI assistants maintaining context across days or weeks, long-running coding assistants working on multi-file projects, research companions accumulating knowledge over extended investigations, or any agent requiring persistent memory across many sessions.
The cost is complexity: the agent must learn effective memory management policies, and poorly tuned hierarchies can lead to critical information being abstracted away too aggressively.
Unified Memory Frameworks: Learning Memory Management
The most recent innovation is unified memory frameworks that treat memory operations as learned behaviors rather than hardcoded policies. Agentic Memory (AgeMem), introduced in January 2026, exemplifies this approach.
AgeMem integrates long-term memory (LTM) and short-term memory (STM) management directly into the agent's policy. Instead of predefined rules for when to store, retrieve, or discard memories, the agent learns these decisions via reinforcement learning. Memory operations (Store, Retrieve, Update, Summarize, Discard) are exposed as tool-based actions, and the agent autonomously decides when and how to invoke them based on task context.
The training strategy uses a three-stage progressive RL approach:
- Stage 1 (LTM construction): Learn to build a useful long-term memory by storing and organizing information from interactions
- Stage 2 (STM management): Learn to manage limited short-term memory capacity by deciding what to retain in context versus flush to LTM
- Stage 3 (Unified behavior): Jointly optimize LTM and STM operations for task performance
This approach avoids the brittleness of handcrafted policies. The agent adapts its memory behavior to the task distribution: knowledge-heavy tasks (like research assistants) learn to store more semantic facts, while procedural tasks (like coding assistants) prioritize workflow memories.
The challenge is training cost. AgeMem requires extensive RL training with task-specific reward signals, making it less accessible for teams without significant ML infrastructure. However, the resulting agents exhibit more robust, context-aware memory behavior than rule-based systems.
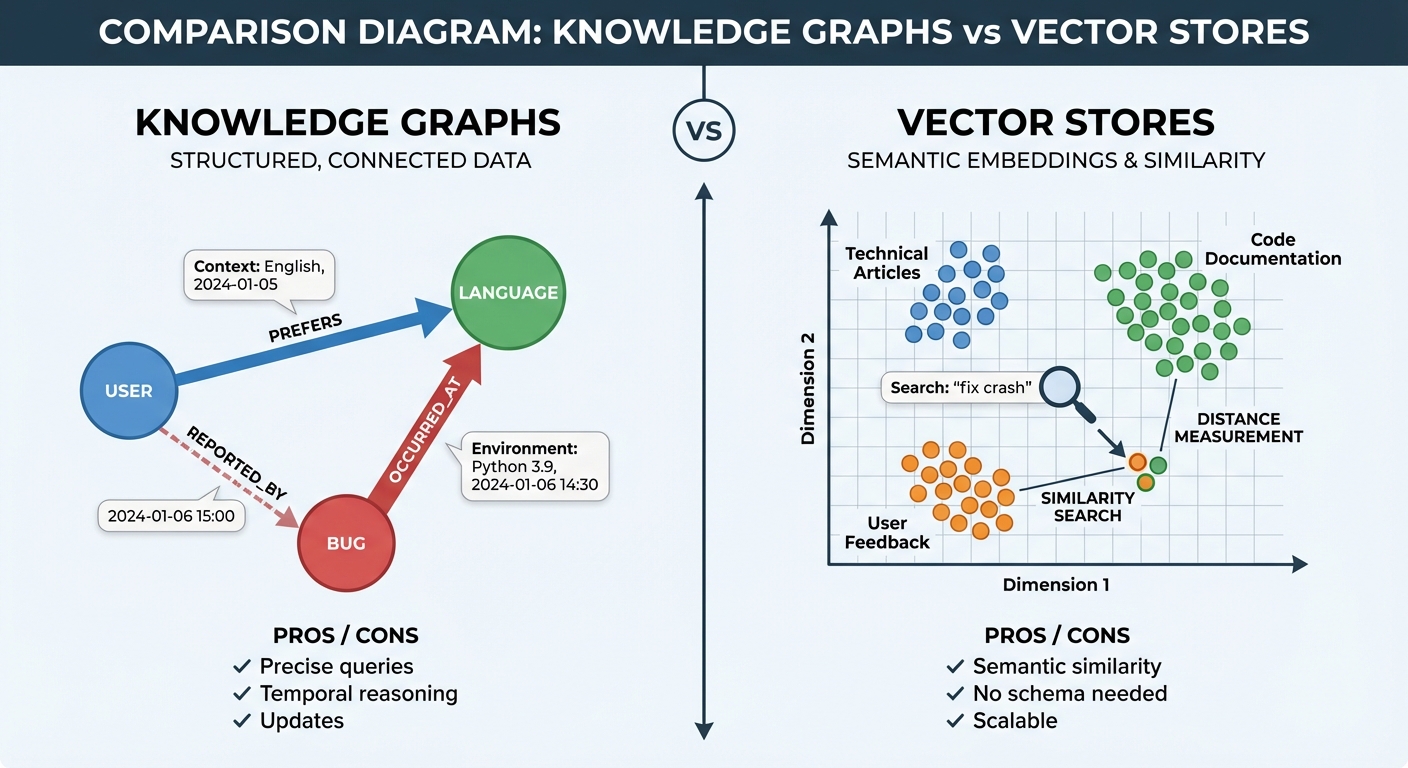
Knowledge Graphs vs. Vector Stores: Structured vs. Semantic Memory
A recurring architectural decision is whether to represent long-term memory as vector embeddings (semantic search) or knowledge graphs (structured queries).
Vector stores excel at semantic similarity: "Find memories related to authentication issues" retrieves embeddings with high cosine similarity to the query. This works well for unstructured knowledge and requires minimal schema design. The downside is immutability (stored texts can't be updated, only replaced) and false positives (semantically similar but contextually irrelevant memories).
Knowledge graphs represent information as structured nodes and edges: User(Alice) --PREFERS--> Language(TypeScript), Bug(#1234) --OCCURRED_AT--> Date(2026-01-15). This enables precise queries ("Show all bugs reported after January 1st") and supports updates (edges can have valid_from and invalid_at timestamps for temporal reasoning). The cost is upfront schema design and the challenge of extracting structured facts from unstructured conversations.
Hybrid approaches combine both: use knowledge graphs for structured facts and temporal relationships, and vector stores for unstructured experiential memories. This is the pattern implemented by several production agent platforms, including Akka's agentic framework and Mem0's universal memory layer.
Implementation: Memory Consolidation Strategies
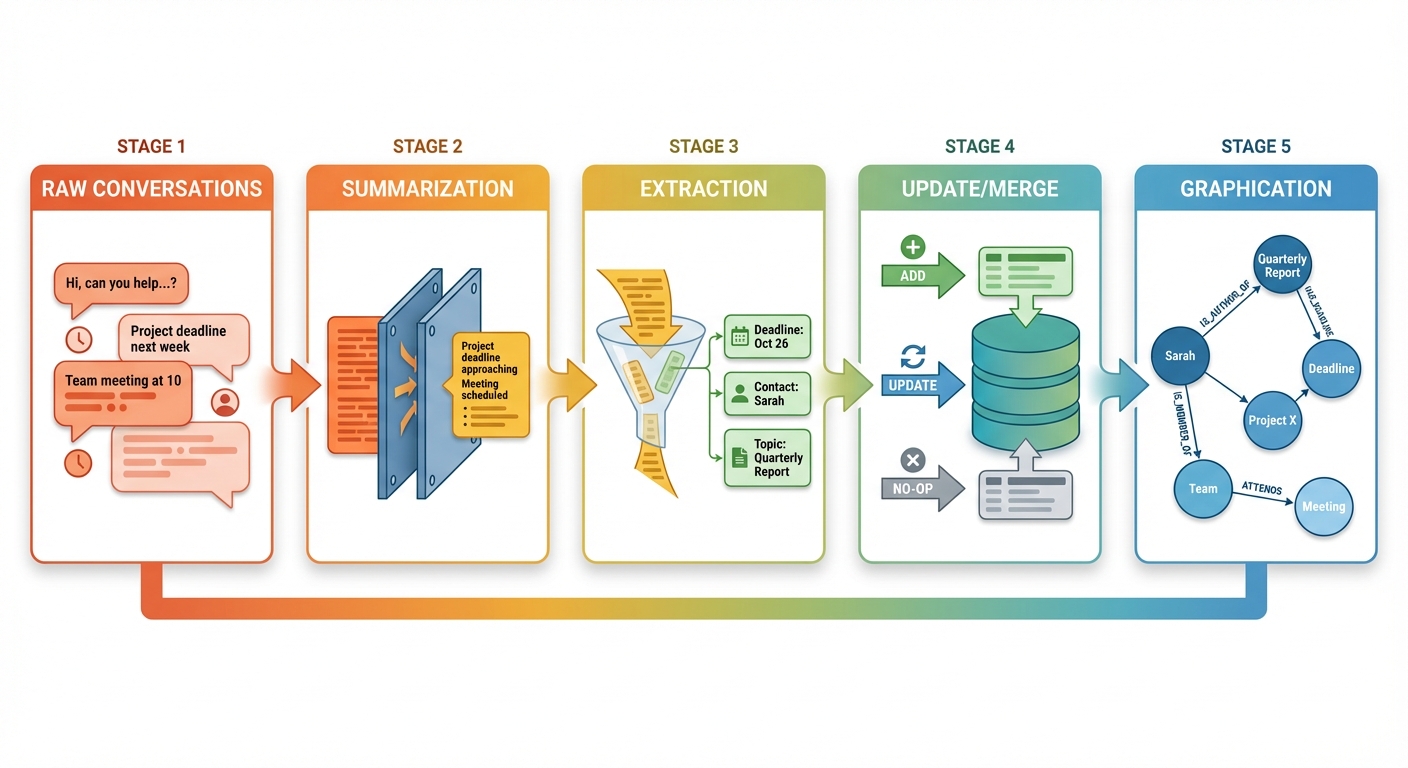
Architecture defines structure; consolidation defines behavior. How does raw interaction history transform into structured, queryable memory? The strategy determines memory quality, which directly impacts agent performance.
Summarization: Compression with Loss
The simplest consolidation strategy is summarization: when short-term memory fills, invoke an LLM to generate a compressed summary of older context and replace the original with the summary.
LangChain's ConversationSummaryMemory exemplifies this pattern:
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
# Conversations are automatically summarized when buffer fills
memory.save_context(
{"input": "I'm working on a React project with TypeScript"},
{"output": "Great! TypeScript provides excellent type safety for React components."}
)
memory.save_context(
{"input": "I prefer functional components with hooks"},
{"output": "I'll remember that. Functional components with hooks are the modern React pattern."}
)
# As more turns accumulate, older messages are summarized
# memory.buffer contains: "The user is working on a React TypeScript project
# and prefers functional components with hooks."The advantage is simplicity and token efficiency. The disadvantage is information loss: summaries discard details, and repeated summarization compounds the loss. This works for short-lived sessions but fails for agents requiring precise recall of earlier interactions.
Extraction: Structured Fact Mining
Extraction strategies parse conversations to identify and store specific facts, preferences, or entities. Instead of preserving raw text, the system extracts structured records:
# Conversation turn
user_message = "I prefer using TypeScript for new projects."
# Extracted memory record
{
"type": "preference",
"user_id": "alice",
"preference": "TypeScript",
"domain": "programming_languages",
"timestamp": "2026-01-31T10:30:00Z",
"confidence": 0.95
}AWS AgentCore Memory uses extraction-based consolidation, prompting the LLM to analyze conversations and generate memory records based on configurable strategies (semantic facts, user preferences, or narrative summaries). The extracted records are stored in a vector database for retrieval.
Extraction enables targeted querying and reduces false positives compared to raw text embeddings. The challenge is extraction quality: poorly designed prompts miss critical information or hallucinate facts not present in the conversation. The consolidation prompt becomes a critical engineering surface.
Update and Merge: Handling Conflicting Information
Static memory stores accumulate contradictions over time: "User prefers JavaScript" followed later by "User now prefers TypeScript." Without an update mechanism, both facts persist, and the agent must resolve the conflict at query time.
Dynamic memory systems implement UPDATE operations that merge new information with existing records. AgentCore Memory uses a three-decision consolidation model:
- ADD: New information introduces a novel fact not previously stored
- UPDATE: New information modifies or supersedes existing facts
- NO-OP: New information is redundant with existing memories
The consolidation LLM retrieves similar existing memories, compares them with the new information, and decides which operation to apply. This maintains consistency while preserving an immutable audit trail (old versions remain accessible for debugging).
The challenge is designing update logic for complex facts. "User prefers TypeScript for frontend but JavaScript for backend" requires nuanced merging, not simple replacement. Effective implementations use structured schemas that support partial updates and multi-valued fields.
Graphication: Relationships and Temporal Reasoning
The most sophisticated consolidation strategy is graphication: extracting entities and relationships to populate a knowledge graph. Instead of storing isolated facts, the system builds a connected web of knowledge supporting multi-hop reasoning.
Example:
# Conversation
conversation = """Last week I deployed the authentication service,
but it had a memory leak. I fixed it yesterday."""
# Extracted knowledge graph
{
"nodes": [
{"id": "auth_service", "type": "Service", "name": "authentication"},
{"id": "bug_1", "type": "Bug", "name": "memory_leak"},
{"id": "date_1", "type": "Date", "value": "2026-01-24"},
{"id": "date_2", "type": "Date", "value": "2026-01-30"}
],
"edges": [
{"from": "auth_service", "to": "bug_1", "relation": "HAS_ISSUE"},
{"from": "bug_1", "to": "date_1", "relation": "OCCURRED_AT"},
{"from": "bug_1", "to": "date_2", "relation": "RESOLVED_AT"},
{"from": "user", "to": "auth_service", "relation": "DEPLOYED"}
]
}This structure enables temporal queries ("What bugs were reported last week?"), causal reasoning ("What issues did deploying auth cause?"), and relationship traversal ("Show all services with open bugs").
The cost is extraction complexity. Building accurate knowledge graphs from natural language conversations requires sophisticated NLP (named entity recognition, relation extraction, temporal parsing) or powerful LLM prompting. Errors compound as the graph grows, requiring validation and correction mechanisms.
Despite the complexity, graphication is increasingly viable with modern LLMs. Agentic systems using LangGraph or CrewAI are adopting knowledge graphs for procedural memory (workflow graphs) and semantic memory (fact graphs), leveraging LLM-based extraction to avoid manual schema population.
Cost Considerations for Consolidation
Memory consolidation isn't free. Each strategy imposes different cost profiles that impact production viability:
Summarization costs:
- LLM API calls: 1 call per consolidation cycle (typically every 10-20 turns)
- Token usage: Input tokens = conversation segment (500-2000 tokens), Output = summary (100-300 tokens)
- Latency: Adds 200-500ms per consolidation if synchronous, negligible if async
- Estimated cost: $0.001-0.005 per consolidation cycle (GPT-4 pricing)
Extraction costs:
- LLM API calls: 1 extraction prompt per consolidation
- Vector storage: $0.10-0.40 per million embeddings (Pinecone, typical)
- Token usage: Similar to summarization but requires structured output parsing
- Estimated cost: $0.002-0.008 per consolidation + storage costs
Update/Merge costs:
- LLM API calls: 2-3 calls (retrieve similar memories, compare, decide operation)
- Retrieval operations: Vector similarity search ($0.001 per 1000 queries)
- Additional token usage for comparison prompts
- Estimated cost: $0.005-0.015 per update operation
Graphication costs:
- LLM API calls: Entity extraction + relationship extraction (2-4 calls)
- Graph database storage: Neo4j Aura starts at $65/month, self-hosted variable
- Most expensive consolidation strategy due to multi-stage processing
- Estimated cost: $0.010-0.030 per graphication cycle
Trade-off strategy: For cost-sensitive applications, use hybrid consolidation: lightweight summarization for routine interactions, expensive extraction/graphication only for critical turns (errors, explicit user preferences, significant events). This reduces consolidation costs by 60-80% while preserving memory quality for important information.
Recent Innovations: State of the Art in 2025-2026
The field of agent memory has seen rapid advancement in the past 18 months. Several systems introduced in late 2025 and early 2026 represent the current frontier.
AgeMem: Unified Memory Learning (January 2026)
Agentic Memory (AgeMem), published in January 2026, introduces the first fully learned memory management system for LLM agents. Unlike prior work that hardcodes memory policies, AgeMem trains agents to autonomously manage both long-term and short-term memory via reinforcement learning.
Key contributions:
- Tool-based memory operations: Exposes Store, Retrieve, Update, Summarize, and Discard as callable actions
- Three-stage progressive training: Separately trains LTM construction, STM management, and unified behaviors
- Adaptive policies: Agents learn task-specific memory strategies rather than following universal rules
Experimental results demonstrate substantial improvements on long-horizon tasks requiring memory. On the SWE-bench coding benchmark, AgeMem-enhanced agents show improved issue resolution by maintaining context about codebase patterns and previous debugging attempts. For personalized assistant tasks, agents equipped with AgeMem demonstrate better user preference adherence and contextual awareness across sessions compared to stateless baselines.
The practical implication is that memory management becomes a trainable behavior rather than an engineering problem. Teams can fine-tune AgeMem-style agents on their specific task distributions, allowing the agent to discover domain-specific memory strategies.
HiMem: Hierarchical Long-Term Memory (January 2026)
HiMem, also published in January 2026, addresses memory for long-horizon conversational agents by introducing a two-layer hierarchical structure:
Episode Memory: Fine-grained interaction segments preserved with temporal grounding. Uses "Topic-Aware Event-Surprise Dual-Channel Segmentation" to identify episode boundaries based on semantic shifts and unexpected events.
Note Memory: Stable, abstract knowledge extracted via multi-stage processing from episode memory. Notes represent facts, preferences, and generalizations that persist across episodes.
The hierarchy enables efficient retrieval: queries first search note memory for abstract matches, then drill into specific episodes when detailed context is needed. This avoids the distraction problem common in flat memory stores, where irrelevant details overwhelm the context.
HiMem demonstrates strong performance on long-context benchmarks (MMLU, BBH, RULER) and long-running conversational tasks, achieving 97% accuracy on needle-in-haystack retrieval compared to 84% for baseline agents.
AWS AgentCore Memory (October 2025)
Amazon Bedrock's AgentCore Memory service, launched in October 2025, provides production-grade memory infrastructure for enterprise agents. It implements both short-term session memory and long-term consolidated memory with three configurable strategies:
- Semantic memory: Facts and general knowledge extracted from conversations
- User preferences: Personal preferences and behavioral patterns
- Summary memory: Narrative summaries of past interactions
The consolidation pipeline uses LLMs to extract meaningful insights, retrieve similar existing memories, and decide whether to ADD, UPDATE, or perform NO-OP operations. The system maintains an immutable audit trail, allowing rollback and debugging of memory evolution.
AgentCore's production focus addresses operational concerns often neglected in research systems: observability (tracking what memories were created and why), consistency (handling concurrent updates), and scalability (supporting millions of user-specific memory stores). This makes it a practical reference architecture for enterprise deployments.
LangMem and Procedural Memory (2025)
LangMem, part of the LangChain ecosystem, introduced dedicated support for procedural memory in 2025. Instead of storing procedural knowledge in static system prompts, LangMem allows agents to store and update instructions dynamically in long-term memory.
This enables true adaptability: agents can learn new procedures from feedback, update workflows based on outcomes, and maintain user-specific process customizations. The canonical example is an email triage assistant that learns classification rules from user corrections, storing updated rules in procedural memory rather than requiring manual prompt updates.
The architectural pattern treats system prompts as data rather than code, allowing runtime modification without redeployment. This shifts agentic systems from "configured once" to "continuously learning," a critical capability for long-term autonomous operation.
Architectural Challenges and Trade-offs
Despite recent advances, several fundamental challenges remain unresolved in agent memory systems.
Memory Capacity and Hardware Constraints
Agentic AI systems with persistent memory create unique infrastructure demands. Unlike stateless LLM inference (process request, discard state), agents maintain long-lived KV caches and persistent memory stores across many interactions. This shifts the bottleneck from compute to memory capacity and bandwidth.
A January 2026 article in The Register highlighted this issue: agentic AI strains modern memory hierarchies by requiring persistent KV caches across multi-step workflows. GPU HBM (High-Bandwidth Memory) is fast but expensive and limited; system DRAM has capacity but massive bandwidth gaps compared to HBM. Transferring large KV caches between GPU and CPU memory creates latency stalls.
The architectural response involves memory hierarchy optimization: hot memories (frequently accessed recent context) stay in GPU HBM, warm memories (recent but less active) move to system DRAM, and cold memories (archived long-term context) go to storage with async prefetch. This mirrors CPU cache hierarchy but at much larger scales.
Emerging technologies like CXL (Compute Express Link) that provide coherent, high-bandwidth access to pooled memory may alleviate these bottlenecks, but they remain nascent. For now, agent memory architectures must carefully manage the GPU-CPU memory trade-off to avoid becoming bandwidth-bound.
Context Poisoning and Retrieval Precision
Vector-based memory retrieval suffers from false positives: semantically similar but contextually irrelevant memories contaminate the context. A query about "authentication issues" might retrieve memories about "authorization problems" or "login UI bugs," diluting the signal with noise.
This "context poisoning" degrades reasoning quality. Studies show that beyond a certain retrieval threshold (typically 5-10 documents), additional retrieved context actively harms performance by overwhelming the LLM with distraction.
Solutions involve:
- Reranking: Use a two-stage retrieval (broad initial search, then LLM-based relevance reranking)
- Metadata filtering: Combine semantic search with structured filters (temporal, categorical)
- Hybrid search: Blend vector similarity with keyword matching for precision
- Adaptive retrieval: Let the agent decide how many memories to retrieve based on task complexity
The challenge is that these solutions add latency and complexity. Production systems must balance retrieval precision against response time, often settling for "good enough" rather than "perfect" recall.
Temporal Reasoning and Memory Decay
Human memory naturally degrades over time, prioritizing recent experiences. Agent memory systems typically lack decay mechanisms, treating all memories as equally valid regardless of age. This creates problems:
- Outdated information persists indefinitely
- Old facts conflict with recent updates
- Memory stores grow without bound
Implementing effective decay requires solving several problems:
- Relevance decay: How quickly should memories lose salience?
- Event-based decay: Should critical events (e.g., errors) decay slower than routine interactions?
- Reactivation: Should retrieved memories be "refreshed" to prevent decay?
- Immutability vs. deletion: Should old memories be deleted or marked as deprecated?
Knowledge graphs naturally support temporal reasoning via edge timestamps (valid_from, valid_until), but vector stores do not. Hybrid architectures that combine both can implement nuanced decay policies, but this adds implementation complexity.
Privacy, Security, and Memory Governance
Persistent agent memory introduces privacy and security concerns. If an agent remembers everything, what happens when:
- A user requests deletion of their data (GDPR compliance)?
- An agent is shared across multiple users with different access rights?
- Sensitive information (credentials, PII) is inadvertently stored in memory?
- An attacker gains access to the memory store?
Production memory systems require:
- Access control: User-specific memory namespaces with isolation
- Encryption: At-rest and in-transit encryption for stored memories
- Audit trails: Logging of memory operations for compliance
- Deletion mechanisms: Hard delete vs. soft delete for regulatory compliance
- Sanitization: Detecting and redacting sensitive information before storage
These are not theoretical concerns. The OpenClaw/Moltbook security incidents in January 2026 exposed numerous agent instances with cleartext API keys and credentials stored in memory, with some gateways completely open to the public internet without authentication. The incidents prompted emergency security hardening and highlighted the risks of moving fast without security-first design.
Architecture Decision Guide
Choosing the right memory architecture depends on your specific use case. Here's a quick reference:
| Architecture Pattern | Best For | Complexity | Session Length | Cost | Example Use Cases | |---------------------|----------|------------|----------------|------|-------------------| | Vector Store + Session State | Short, focused interactions | Low | 5-20 turns | Low | Customer support bots, FAQ assistants, simple chatbots | | Hierarchical Memory (MemGPT) | Long-running conversational agents | Medium | 100+ turns, multi-day | Medium | Personal assistants, research companions, project management | | Unified Framework (AgeMem) | Adaptive, task-specific agents | High | Variable, task-dependent | High | Autonomous coding assistants, domain-specific experts | | Hybrid (KG + Vector) | Complex reasoning with structured data | High | Variable | High | Enterprise knowledge systems, debugging assistants, compliance trackers |
Implementation Checklist
Before building an agent memory system, address these key decisions:
Memory Architecture:
- [ ] Define required memory types (episodic, semantic, procedural)
- [ ] Choose storage backend (vector DB: Pinecone/Qdrant/Chroma, graph DB: Neo4j, or hybrid)
- [ ] Determine consolidation strategy (summarization, extraction, graphication)
- [ ] Set consolidation frequency (per-turn, batched, on-demand)
Retrieval & Performance:
- [ ] Implement retrieval filtering (temporal queries, metadata filters, hybrid search)
- [ ] Set retrieval limits (top-k documents, reranking strategy)
- [ ] Design memory decay/retention policies (TTL, importance-based, event-triggered)
- [ ] Optimize for latency (caching, prefetch, async consolidation)
Governance & Security:
- [ ] Add privacy controls (namespace isolation, user-specific memory stores)
- [ ] Implement encryption (at-rest and in-transit)
- [ ] Set up audit trails (memory operation logging for compliance)
- [ ] Define deletion mechanisms (hard delete vs soft delete, GDPR compliance)
- [ ] Sanitize sensitive data (PII detection, credential filtering)
Observability:
- [ ] Track memory operations (what was stored, retrieved, when, why)
- [ ] Monitor consolidation quality (extraction accuracy, summary coherence)
- [ ] Measure retrieval precision (relevance metrics, false positive rates)
- [ ] Alert on anomalies (memory bloat, high latency, failed consolidations)
Future Directions
The trajectory of agent memory research points toward several emerging directions.
Multi-Modal Memory
Current memory systems are text-centric, but agents increasingly operate in multi-modal contexts (images, audio, code, structured data). Future memory architectures must handle:
- Visual episodic memory (screenshots, diagrams)
- Audio experiences (transcribed meetings, voice interactions)
- Code artifacts (functions written, bugs fixed)
- Structured data (database schemas, API specs)
This requires multi-modal embeddings (CLIP-style models), multi-modal consolidation (extracting structured facts from images), and multi-modal retrieval (finding relevant images given text queries). The foundational models exist, but integration into production agent memory systems remains nascent.
Federated and Collaborative Memory
Agents increasingly work in teams, raising questions about shared memory. Should agents share episodic memories, semantic knowledge, or procedural workflows? How do agents reconcile conflicting memories from different perspectives?
Federated memory architectures allow agents to maintain private memories while selectively sharing curated knowledge with a team memory pool. This mirrors human organizations: individuals remember personal experiences but contribute to shared organizational knowledge bases.
Research in collaborative memory for multi-agent systems is active but early-stage. LangGraph's support for cross-agent working memory provides basic infrastructure, but sophisticated consolidation, conflict resolution, and access control for team memory remain open problems.
Continual Learning and Memory Consolidation
Current agent memory is largely static after initial training. The agent accumulates new episodic memories but doesn't update its base knowledge (model parameters) from experience. This creates a gap between what the agent "knows" (parametric knowledge) and what it "remembers" (external memory).
Future systems may implement continual learning: periodically fine-tuning the base model on consolidated memories to internalize frequently used knowledge. This reduces retrieval overhead (knowledge moves from external memory to parameters) and improves reasoning quality (internalized knowledge integrates seamlessly with parametric reasoning).
The challenge is catastrophic forgetting: updating parameters risks degrading performance on unrelated tasks. Techniques from continual learning research (elastic weight consolidation, experience replay) may enable safe parameter updates, but integration with agent memory systems is unexplored territory.
Memory-Augmented Tool Use
Tools extend agent capabilities, but current architectures treat tools and memory separately. An emerging pattern is memory-augmented tool use: tools that query agent memory to provide context-aware functionality.
Example: A code generation tool that queries procedural memory ("How did I solve similar problems before?") and semantic memory ("What libraries does this user prefer?") to generate personalized, contextually relevant code.
This inverts the typical flow: instead of the agent querying memory then calling tools, tools directly access memory to improve their outputs. This requires exposing memory as a first-class API surface that tools can query, blurring the boundary between agent reasoning and tool execution.
Conclusion
Memory is the infrastructure that transforms reactive LLMs into autonomous agents. Without persistent, structured memory, agents remain stateless responders constrained by context windows and doomed to forget everything between sessions. With effective memory architectures, agents can learn from experience, maintain long-term goals, personalize to individual users, and operate autonomously over extended time horizons.
The theoretical foundations draw from cognitive science: working memory for active processing, episodic memory for experiences, semantic memory for facts, and procedural memory for skills. These map to architectural patterns: session state management, vector databases for retrieval, knowledge graphs for structured reasoning, and workflow systems for skill execution.
Implementation hinges on consolidation strategies: how raw interactions transform into queryable memory. Summarization compresses with loss, extraction mines structured facts, update operations maintain consistency, and graphication builds relational knowledge. Recent innovations like AgeMem and HiMem demonstrate that memory management itself can be learned rather than hardcoded, opening paths toward more adaptive, robust memory systems.
Challenges remain: memory capacity and bandwidth constraints, context poisoning from imprecise retrieval, temporal reasoning and decay mechanisms, and privacy/security governance. These are not merely engineering hurdles but fundamental architectural questions shaping the future of agentic AI.
As agents become more capable and autonomous, memory architectures will determine whether they are useful assistants or frustrating goldfish. The systems we build today—hierarchical, learned, multi-modal, collaborative—define the cognitive capabilities of tomorrow's autonomous agents. The question is not whether agents need memory, but what kinds of memory enable genuine autonomy.
Sources
- The Brains Behind the Bots: A Comprehensive Guide to AI Agent Memory in 2026 - Medium
- Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents - arXiv
- How to Design Efficient Memory Architectures for Agentic AI Systems - Towards AI
- Memory in Agentic AI Systems: The Cognitive Architecture Behind Intelligent Collaboration - Genesis
- Memory-augmented agents - AWS Prescriptive Guidance
- Build smarter AI agents: Manage short-term and long-term memory with Redis
- How agentic AI can strain modern memory hierarchies - The Register
- HiMem: Hierarchical Long-Term Memory for LLM Long-Horizon Agents - arXiv
- Building smarter AI agents: AgentCore long-term memory deep dive - AWS ML Blog
- Improved Long & Short-Term Memory for LlamaIndex Agents
- Semantic vs Episodic vs Procedural Memory in AI Agents - Medium
- AI Agent Memory: What, Why and How It Works - Mem0
- What Is AI Agent Memory? - IBM
- Building Agent with Semantic, Episodic & Procedural Memory - Substack
- Agentic AI Frameworks: Top 8 Options in 2026 - NetApp Instaclustr
- Memory for AI Agents: A New Paradigm of Context Engineering - The New Stack